프로젝트 진행도중 특정 테이블에 특정 구분자값으로 구분된 문자열을 통으로 넣어줄테니 알아서 파싱하여 쓰세요같은 불친절한 일이 발생했습니다.
처음에 처리방법으로 생각한건 java에서 일정시간마다 스케줄러가 데이터를 수집하고 해당데이터들을 구문별로 나누고 테이블에 insert해주는 방법을 생각했지만, 데이터가 꼬일 우려가 있어 Flag처리를 통한 방법... 또는 스케줄러 동작이 끝나기전에 또 스케줄러가 돌아야 하는 경우가 발생하거나 등등... 여러 문제가 예상되었습니다....
아이디어 회의를 통해 해결 방법으로 제시된게 문자열을 넣어주면 바로 mysql trigger를 사용해보자였고, 예전에 pg에서 사용해본 기억이 있어서 mysql에서 진행해보았습니다.
총에서 방아쇠를 당기면 총알이 날라가듯 여기서 trigger란 특정 테이블에 어떤 행동 이벤트가 발생하면 발동하는 것을 말합니다.
여기서 이벤트로는 특정 테이블에 INSERT, UPDATE, DELETE가 일어나면 발동 시킬 수 있고, 실행되는 순서도 지정할 수 있습니다. INSERT행위가 일어나기 전에 처리하려면 BEFORE INSERT행위가 일어나고 처리하려면 AFTER 키워드를 사용합니다.
바로 생성방법 사용법을 알아보겠습니다. 급하신분들은 맨 아래로 내려가면 최종 트리거를 볼 수 있습니다.
Trigger 생성하기
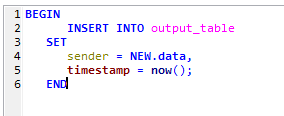
DROP TRIGGER IF EXISTS parserTrigger;
delimiter $$
CREATE TRIGGER parserTrigger
AFTER INSERT ON input_table
FOR EACH ROW
BEGIN
INSERT INTO output_table
SET
sender = NEW.data,
timestamp = now();
END
$$delimiter;이미 같은 이름의 트리거가 존재할경우 지우기 위해 DROP TRIGGER를 사용하였고
CREATE TRIGGER를 통해 트리거의 이름을 parserTrigger라고 만들었습니다.
delimiter라는 키워드도 보이실텐데 생소한분들도 많을 것 같습니다. 제가 지금 생소하거든요.
delimiter는 트리거의 구문을 시작하고 끝내는 키워드라고 합니다. 즉 트리거들의 구분을 위한 키워드로 생각하시면 됩니다.
input_table 테이블에 INSERT동작이 발생하면 data컬럼의 값을 가져와 output_table에 넣어주는 INSERT -> INSERT 트리거를 생성했습니다.
실제 동작 테스트


정상적으로 데이터가 인입된 것을 볼 수 있습니다.
응용편 - 특정 문자열을 구분값으로 나누어 집어넣기
이번에는 기본 생성방식에서 응용하여 어떤 문자열이 들어오고 ';'구분값으로 나누어 들어온 데이터를 행으로 입력하는 트리거를 작성해보겠습니다.
작업 준비를 위해 테이블을 생성합니다.
input_table
먼저 insert가 들어올 테이블입니다
CREATE TABLE IF NOT EXISTS `input_table` (
`idx` int(11) NOT NULL AUTO_INCREMENT,
`data` varchar(6500) NOT NULL DEFAULT '0',
PRIMARY KEY (`idx`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
output_table
input_table에 insert가 일어나면 trigger를 통해 받을 테이블입니다.
CREATE TABLE IF NOT EXISTS `output_table` (
`idx` int(11) NOT NULL AUTO_INCREMENT,
`type` varchar(50) NOT NULL,
`value` varchar(50) NOT NULL,
`timestamp` timestamp NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`idx`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;idx: pk용 sequence값 입니다.
type : key값이 들어갈 컬럼입니다. ex) type1, type2, type3...
value : key에 해당하는 값이 들어갈 컬럼입니다. ex) 5, 7, 29
timestamp: trigger 동작시간인 now()를 넣을 컬럼입니다.
이제 트리거를 만듭니다.
문자열를 잘라서 넣어주는 Trigger
DROP TRIGGER IF EXISTS parserTrigger;
delimiter $$
CREATE TRIGGER parserTrigger
AFTER INSERT ON input_table
FOR EACH ROW
BEGIN
DECLARE type1 varchar(100);
DECLARE type2 varchar(100);
DECLARE type3 varchar(100);
SET type1 = substring_index(substring_index(NEW.data, ';', 1), ':', -1);
SET type2 = substring_index(substring_index(NEW.data, ';', 2), ':', -1);
SET type3 = substring_index(substring_index(NEW.data, ';', 3), ':', -1);
INSERT INTO output_table (type, value, timestamp) values ('type1', type1, now());
INSERT INTO output_table (type, value, timestamp) values ('type2', type2, now());
INSERT INTO output_table (type, value, timestamp) values ('type3', type3, now());
END;
$$delimiter;
이번엔 DECLARE라는 키워드가 추가되었습니다.
DECLARE는 트리거의 변수를 생성할때 사용하는 키워드로 변수명 자료형(사이즈) 형태로 입력해주면 됩니다.
예시로 들어올 데이터는 'type1:20;type2:5;type3:15' 형태라고 가정하겠습니다.
;으로 구분되어 있고 ':'의 앞글자는 key, 뒷글자는 value값입니다.
input_table의 data컬럼에 예시데이터('type1:20;type2:5;type3:15' )가 들어오면 substring_indxe를 통해 생성한 변수 type1, 2, 3에 각각 잘라서 값을 넣어주고 값이 비어있지 않다면 각각 INSERT를 처리하는 트리거입니다.
동작을 확인해보겠습니다.

type1에 20
type2에 5
type3에 15
한줄로 들어가 있던 데이터가 정상적으로 들어간 모습을 볼 수 있습니다.
위에서 한 트리거도 동작은 하지만 문제가 있습니다 3개의 데이터가 무조건 있어야 정상동작을 한다는 점입니다.
'type2:5;type3:15' 이것처럼 type1이 안들어오면 버그가 발생합니다.
key값도 받고 길이도 체크할 필요가 있습니다.
최종 완성 - 값이 없으면 넣지 않도록 조건문 추가하기
입력값을 확인하여 동적으로 INSERT하는 TRIGGER
DROP TRIGGER IF EXISTS parserTrigger;
delimiter $$
CREATE TRIGGER parserTrigger
AFTER INSERT ON input_table
FOR EACH ROW
BEGIN
DECLARE dataStr varchar(1000);
DECLARE splitLen INT default 0;
DECLARE type1 varchar(100);
DECLARE type2 varchar(100);
DECLARE type3 varchar(100);
DECLARE typeValue1 varchar(100);
DECLARE typeValue2 varchar(100);
DECLARE typeValue3 varchar(100);
SET dataStr = NEW.data;
SET splitLen = ROUND((CHAR_LENGTH(dataStr) - CHAR_LENGTH(REPLACE(dataStr, ';', '')) / CHAR_LENGTH(';')));
SET type1 = substring_index(substring_index(substring_index(dataStr, ';', 1), ';', -1), ':', 1);
SET type2 = substring_index(substring_index(substring_index(dataStr, ';', 2), ';', -1), ':', 1);
SET type3 = substring_index(substring_index(substring_index(dataStr, ';', 3), ';', -1), ':', 1);
SET typeValue1 = substring_index(substring_index(dataStr, ';', 1), ':', -1);
SET typeValue2 = substring_index(substring_index(dataStr, ';', 2), ':', -1);
SET typeValue3 = substring_index(substring_index(dataStr, ';', 3), ':', -1);
IF type1 is NOT NULL
THEN BEGIN
INSERT INTO output_table (type, value, timestamp) values (type1, typeValue1, now());
END; END IF;
IF splitLen > 0 and type2 is NOT NULL
THEN BEGIN
INSERT INTO output_table (type, value, timestamp) values (type2, typeValue2, now());
END; END IF;
IF splitLen > 1 and type3 is NOT NULL
THEN BEGIN
INSERT INTO output_table (type, value, timestamp) values (type3, typeValue3, now());
END; END IF;
END;
$$delimiter;추가된 것으로는 아래와 같습니다.
dataStr은 입력이 들어온 data컬럼의 값
splitLen은 ';' 특수문자의 개수
type의 키
typeValue는 값
별개로 받는 변수를 처리하여 IF문에 따라 NULL체크와 길이를 체크하여 INSERT를 제어합니다.
동작 확인!

'Databases > Mysql' 카테고리의 다른 글
| Mysql - 특정구분자 문자열을 split하고 검색하기 (0) | 2020.05.15 |
|---|---|
| Mysql - 다중행을 단일행으로 출력하기(group_concat) (0) | 2020.04.21 |
| Mysql - Group by한 데이터들의 마지막(최신) 값만 가져오기 (4) | 2020.02.10 |
| Mysql - date_format 사용하기 포맷형태(%Y-%m-%d) (0) | 2020.02.06 |
| Mysql - join문을 활용한 update처리 (0) | 2020.01.22 |